Spark 组件部署
1、需前置 Hadoop 环境,并检查 Hadoop 环境是否可用,截图并保存结果;
start-all.sh
2、解压 scala 安装包到“etc/local/src”路径下,并更名为 scala,截图并保存结果;
tar -zxvf scala-2.11.8.tgz -C /etc/local/src
mv scala-2.11.8 scala
3、设置 scala 环境变量,并使环境变量只对当前用户生效,截图并保存结果;
SCALA_HOME=/etc/local/src/scala
export PATH=$PATH:$SCALA_HOME/bin
4、进入 scala 并截图,截图并保存结果;
scala -version
scalac -version
scala
5、解压 Spark 安装包到“etc/local/src”路径下,并更名为 spark,截图并保存结果;
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /etc/local/src
mv spark-2.3.0-bin-hadoop2.7 spark
6、设置 Spark 环境变量,并使环境变量只对当前用户生效,截图并保存结果;
export SPARK_HOME=/etc/local/src/spark
export PATH=$SPARK_HOME/bin:$PATH
7、修改 Spark 参数配置,指定 Spark slave 节点,截图并保存结果;
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
#配置如下
#hadoop的配置文件路径,spark会去读取配置文件,如果不在同一个集群,需拷贝配置文件到spark的节点,让spark能够读到
HADOOP_CONF_DIR=/usr/project/hadoop/etc/hadoop
#本机ip
SPARK_LOCAL_IP=master
JAVA_HOME=/usr/local/src/java/jdk
#zookeeper实现spark的高可用
SPARK_MASTER_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=focuson1:2181,focuson2:2181,focuson3:2181-Dspark.deploy.zookeeper.dir=/spark"
cp slaves.template slaves
vi slaves
#配置集群worker
master
slave1
slave2
--------------
export JAVA_HOME=/usr/java/jdk1.8.0_141
export SCALA_HOME=/usr/scala-2.11.7
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
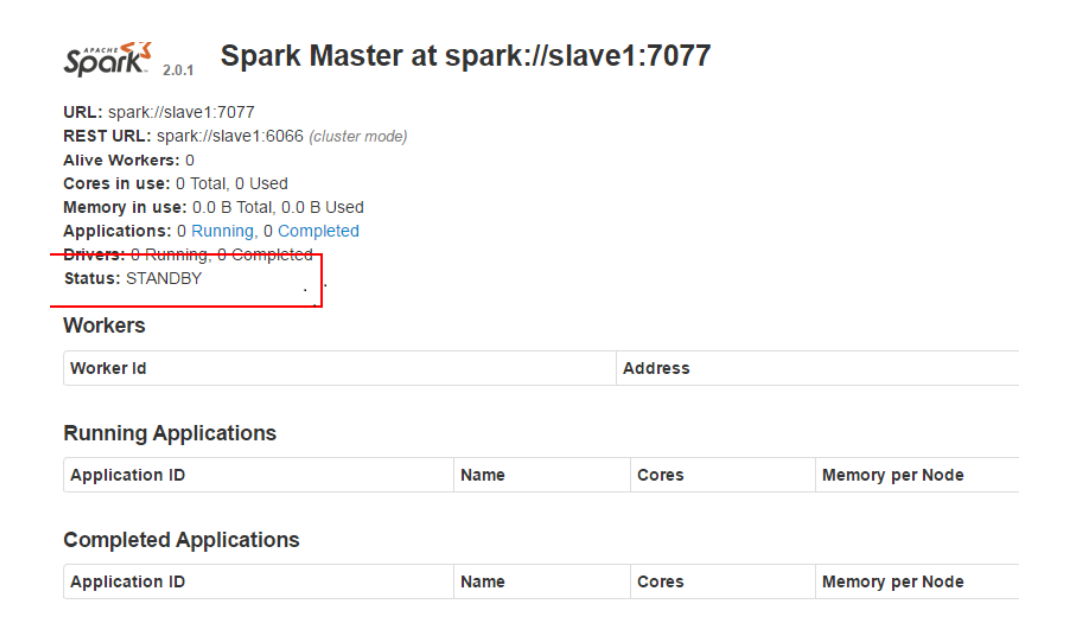
8、启动 Spark,并使用命令查看 webUI 结果,截图并保存结果;
/usr/project/spark/sbin/start-all.sh
master:8080
打开Spark-shell
使用
spark-shell
通过
SparkMaster_IP:4040
访问WebUI查看当前执行的任务。
显示图如以下示例: 主节点
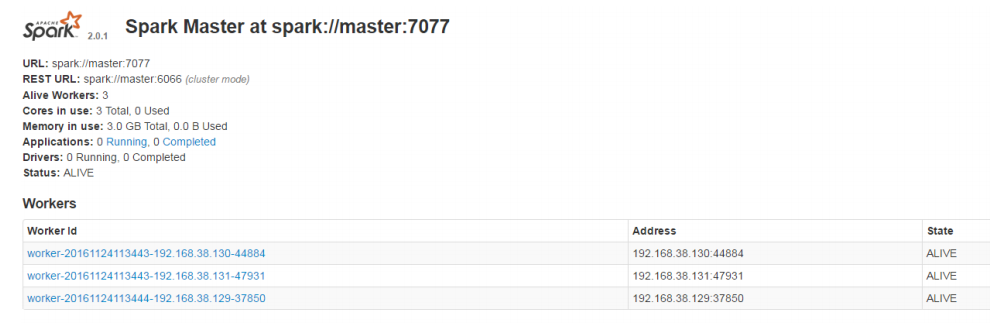
从节点